


Summary: This series outlines the process to diagnose, treat, and manage enterprise content debt, using Firefox add-ons as a case study. This piece walks through the eight steps to develop a new content model:
- Step 1: Stakeholder interviews
- Step 2: Documenting content elements
- Step 3: Data analysis—content quality
- Step 4: Domain expert review
- Step 5: Competitor compare
- Step 6: User research—What content matters?
- Step 7: Creating a content model
- Step 8: Refine and align
Step 1: Stakeholder interviews
To determine a payment plan for our content debt, we needed to first get a better understanding of the product landscape. Over the course of a couple of weeks, the team’s UX researcher and I conducted stakeholder interviews:
Who: Subject matter experts, decision-makers, and collaborators. May include product, engineering, design, and other content folks.
What: Schedule an hour with each participant. Develop a spreadsheet with questions that get at the heart of what you are trying to understand. Ask the same set of core questions to establish trends and patterns, as well as a smaller set specific to each interviewee’s domain expertise.
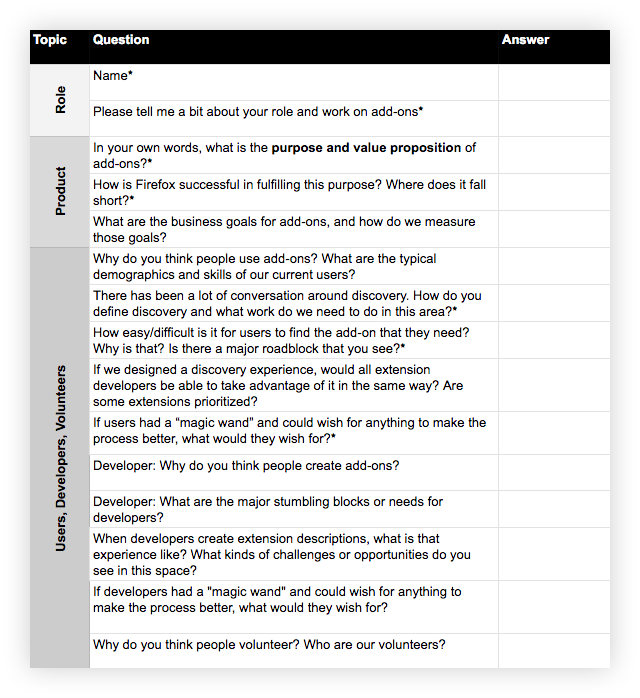
Sample question template, including content-specific inquiries below

After completing the interviews, we summarized the findings and walked the team through them. This helped build alignment with our stakeholders around the issues and prime them for the potential UX and content solutions ahead.
Stakeholder interviews also allowed us to clarify our goals. To focus our work and make ourselves accountable to it, we broke down our overarching goal—improve Firefox users’ ability to discover, trust, install, and enjoy extensions—into detailed objectives and measurements using an objectives and measurements template. Our main objectives fell into three buckets: improved user experience, improved developer experience, and improved content structure. Once the work was done, we could measure our progress against those objectives using the measurements we identified.
Step 2: Documenting content elements
Product environment surveyed, we dug into the content that shaped that landscape.
Extensions are recommended and accessed not only through AMO, but in a variety of places, including the Firefox browser itself, in contextual recommendations, and in external content. To improve content across this large ecosystem, we needed to start small…at the cellular content level. We needed to assess, evolve, and improve our core content elements.
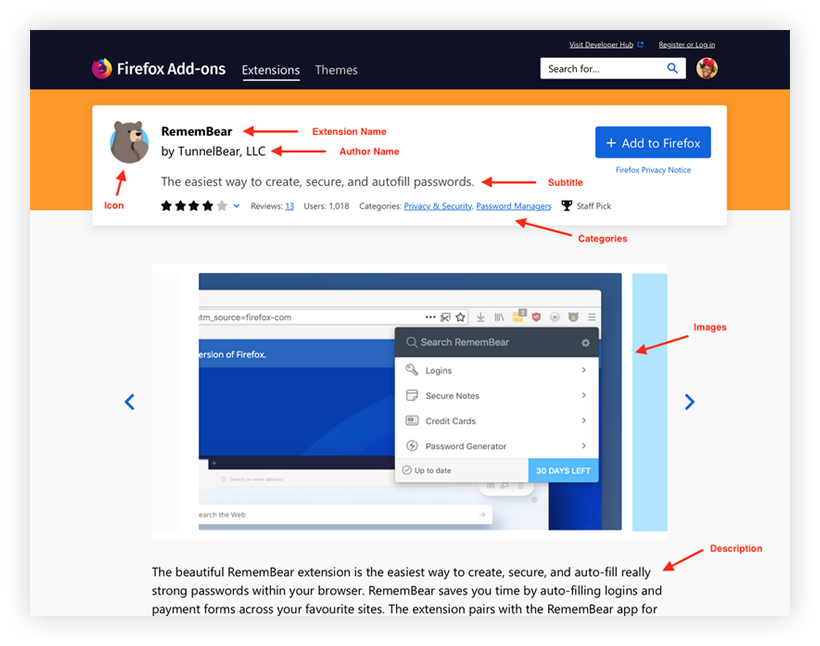
By “content elements,” I mean all of the types of content or data that are attached to an extension—either by developers in the extension submission process, by Mozilla on the back-end, or by users. So, very specifically, these are things like description, categories, tags, ratings, etc. For example, the following image contains three content elements: icon, extension name, summary:

Using Excel, I documented existing content elements. I also documented which elements showed up where in the ecosystem (i.e., “content touchpoints”):
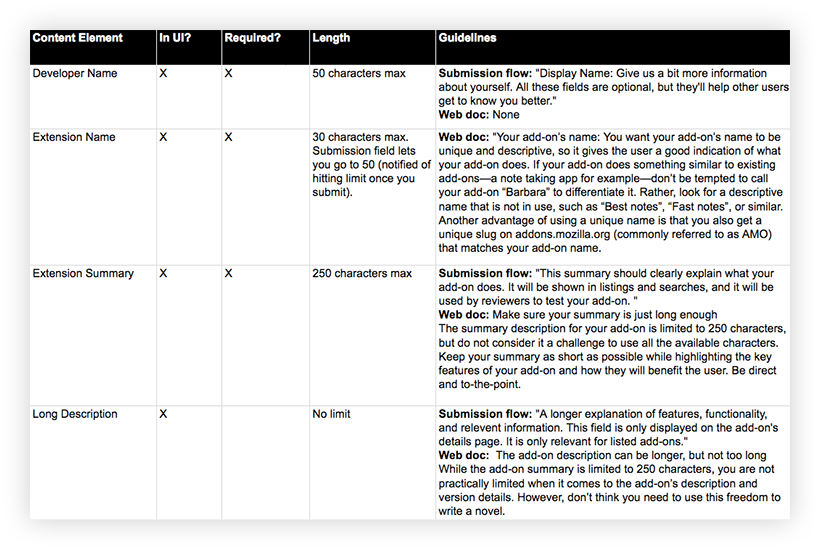
Excerpt of content elements documentation

Excerpt of content elements documentation: content touchpoints
The content documentation Excel served as the foundational document for all the work that followed. As the team continued to acquire information to shape future solutions, we documented those learnings in the Excel, evolving the recommendations as we went.
Step 3: Data analysis—content quality
Current content elements identified, we could now assess the state of said content. To complete this analysis, we used a database query (created by our product manager) that populated all of the content for each content element for every extension and theme. Phew.
We developed a list of queries about the content…
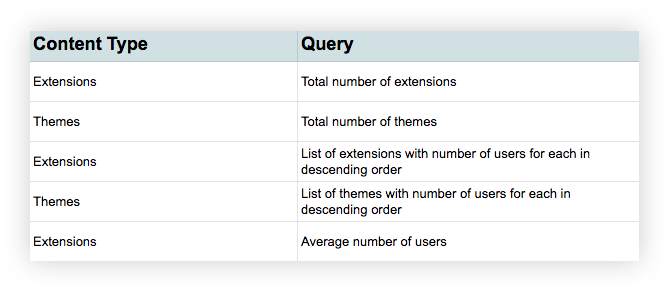
Sample selection of data questions
…and then answered those queries for each content element field.

Sample data analysis for “Extension Name”
- For quantitative questions (like minimum/maximum content length per element), we used Excel formulas.
- For questions of content quality, we analyzed a sub-section of the data. For example, what’s the content quality state of extension names for the top 100 extensions? What patterns, good and bad, do we see?
Step 4: Domain expert review
I also needed input from domain experts on the content elements, including content reviewers, design, and localization. Through this process, we discovered pain points, areas of opportunity, and considerations for the new requirements.
For example, we had been contemplating a 10-character minimum for our long description field. Conversations with localization expert, Peiying Mo, revealed that this would not work well for non-English content authors…while 10 characters is a reasonable expectation in English, it’s asking for quite a bit of content when we are talking about 10 Chinese characters.
Because improving search engine optimization (SEO) for add-ons was a priority, review by SEO specialist, Raphael Raue, was especially important. Based on user research and analytics, we knew users often find extensions, and make their way to the add-ons site, through external search engines. Thus, their first impression of an add-on, and the basis upon which they may assess their interest to learn more, is an extension title and description in Google search results (also called a “search snippet”). So, our new content model needed to be optimized for these search listings.

Sample domain expert review comments for “Extension Name”
Step 5: Competitor compare
A picture of the internal content issues and needs was starting to take shape. Now we needed to look externally to understand how our content compared to competitors and other successful commercial sites.
Philip Walmsley, UX designer, identified those sites and audited their content elements, identifying surplus, gaps, and differences from Firefox. We discussed the findings and determined what to add, trim, or tweak in Firefox’s content element offerings depending on value to the user.
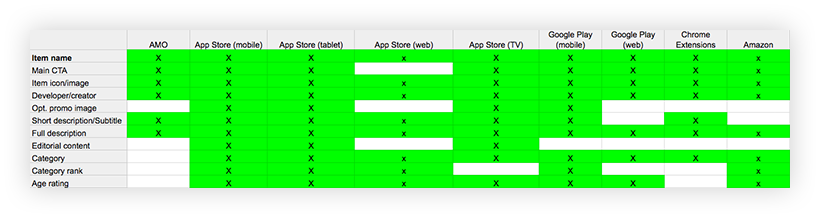
Excerpt of competitive analysis
Step 6: User research—what content matters?
A fair amount of user research about add-ons had already been done before we embarked on this journey, and Jennifer Davidson, our UX researcher, lead additional, targeted research over the course of the year. That research informed the content element issues and needs. In particular, a large site survey, add-ons team think-aloud sessions, and in-person user interviews identified how users discover and decide whether or not to get an extension.
Regarding extension product pages in particular, we asked:
- Do participants understand and trust the content on the product pages?
- What type of information is important when deciding whether or not to get an extension?
- Is there content missing that would aid in their discovery and comprehension?
Through this work, we deepened our understanding of the relative importance of different content elements (for example: extension name, summary, long description were all important), what elements were critical to decision making (such as social proof via ratings), and where we had content gaps (for example, desire for learning-by-video).
Step 7: Creating a content model
“…content modeling gives you systemic knowledge; it allows you to see what types of content you have, which elements they include, and how they can operate in a standardized way—so you can work with architecture, rather than designing each one individually.” —Sara Wachter-Boettcher, Content Everywhere, 31
Learnings from steps 1-6 informed the next, very important content phase: identifying a new content model for an add-ons product page.
A content model defines all of the content elements in an experience. It details the requirements and restrictions for each element, as well as the connections between elements. Content models take diverse shapes and forms depending on project needs, but the basic steps often include documentation of the content elements you have (step 2 above), analysis of those elements (steps 3-6 above), and then charting new requirements based on what you’ve learned and what the organization and users need.
Creating a content model takes quite a bit of information and input upfront, but it pays dividends in the long-term, especially when it comes to addressing and preventing content debt. The add-ons ecosystem did not have a detailed, updated content model and because of that, developers didn’t have the guardrails they needed to create better content, the design team didn’t have the content types it needed to create scalable, user-focused content, and users were faced with varying content quality.
A content model can feel prescriptive and painfully detailed, but each content element within it should provide the flexibility and guidance for content creators to produce content that meets their goals and the goals of the system.

Sample content model for “Extension Name”
Step 8: Refine and align
Now that we had a draft content model—in other words, a list of recommended requirements for each content element—we needed review and input from our key stakeholders.
This included conversations with add-ons UX team members, as well as partners from the initial stakeholder interviews (like product, engineering, etc.). It was especially important to talk through the content model elements with designers Philip and Emanuela, and to pressure test whether each new element’s requirements and file type served design needs across the ecosystem. One of the ways we did this was by applying the new content elements to future designs, with both best and worst-case content scenarios.
Re-designed product page with new content elements (note—not a final design, just a study). Design lead: Philip Walmsley.
Draft “universal extension card” with new content elements (note—not a final design, just a study). This card aims to increase user trust and learnability when user is presented with an extension offering anywhere in the ecosystem. Design lead: Emanuela Damiani.
Based on this review period and usability testing on usertesting.com, we made adjustments to our content model.
Okay, content model done. What’s next?
Now that we had our new content model, we needed to make it a reality for the extension developers creating product pages.
In part 3, I’ll walk through the creation and testing of deliverables, including content guidelines and communication materials.
Thank you to Michelle Heubusch, Jennifer Davidson, Emanuela Damiani, Philip Walmsley, Kev Needham, Mike Conca, Amy Tsay, Jorge Villalobos, Stuart Colville, Caitlin Neiman, Andreas Wagner, Raphael Raue, and Peiying Mo for their partnership in this work.