L20n is a new localization framework for Firefox and Gecko. Here’s what you need to know if you’re a Firefox front-end developer.
Gecko’s current localization framework hasn’t changed in the last two decades. It is based on file formats which weren’t designed for localization. It offers crude APIs. It tasks developers with things they shouldn’t have to do. It doesn’t allow localizers to use the full expressive power of their languages.
L20n is a modern localization and internationalization infrastructure created by the Localization Engineering team in order to overcome these limitations. It was successfully used in Firefox OS. We’ve put parts of it on the ECMA standardization path. Now we intend to integrate it into Gecko and migrate Firefox to it.
Overview of How L20n Works
For Firefox, L20n is most powerful when it’s used declaratively in the DOM. The localization happens on the runtime and gracefully falls back to the next language in case of errors. L20n doesn’t force developers to programmatically create string bundles, request raw strings from them and manually interpolate variables. Instead, L20n uses a Mutation Observer which is notified about changes to data-l10n-* attributes in the DOM tree. The complexity of the language negotiation, resource loading, error fallback and string interpolation is hidden in the mutation handler. It is still possible to use the JavaScript API to request a translation manually in rare situations when DOM is not available (e.g. OS notifications).
What problems L20n solves?
The current localization infrastructure is tightly-coupled: it touches many different areas of the codebase. It also requires many decisions from the developer. Every time someone wants to add a new string they need to go through the following mental checklist:
- Is the translation embedded in HTML or XUL? If so, use the DTD format. Be careful to only use valid entity references or you’ll end up with a Yellow Screen of Death. Sure enough, the list of valid entities is different for HTML and for XUL. (For instance
…
is valid in HTML but not in XUL.) - Is the translation requested dynamically from JavaScript? If so, use the .properties format.
- Does the translation use interpolated variables? If so, refer to the documentation on good practices and use
#1,%S,%1$S,{name}or&name;depending on the use-case. (That’s five different ways of interpolating data!) For translations requested from JavaScript, replace the interpolation placeables manually withString.prototype.replace. - Does the translation depend on a number in any of the supported languages? If so, use the PluralForm.jsm module to choose the correct variant of the translation. Specify all variants on a single line of the .properties file, separated by semicolons.
- Does the translation comprise HTML elements? If so, split the copy into smaller parts surrounding the HTML elements and put each part in its own translation. Remember to keep them in sync in case of changes to the copy. Alternatively write your own solution for replacing interpolation specifiers with HTML markup.
What a ride! All of this just to add a simple You have no new notifications message to the UI. How do we fix this tight-coupled-ness?
L20n is designed around the principle of separation of concerns. It introduces a single syntax for all use-cases and offers a robust fallback mechanism in case of missing or broken translations.
Let’s take a closer look at some of the features of L20n which mitigate the headaches outlined above.
Single syntax
In addition to DTD and .properties files Gecko currently also uses .ini and .inc files for a total of four different localization formats.
L20n introduces a single file format based on ICU’s MessageFormat. It’s designed to look familiar to people who have previous experience with .properties and .ini. If you’ve worked with .properties or .ini before you already know how to create simple L20n translations.

Fig. 1. A primer on the FTL syntax
A single localization format greatly reduces the complexity of the ecosystem. It’s designed to keep simple translations simple and readable. At the same time it allows for more control from localizers when it comes to defining and selecting variants of translations for different plural categories, genders, grammatical cases etc. These features can be introduced only in translations which need them and never leak into other languages. You can learn more about L20n’s syntax in my previous blog post and at http://l20n.org/learn. An interactive editor is also available at https://l20n.github.io/tinker.
Separation of Concerns: Plurals and Interpolation
In L20n all the logic related to selecting the right variant of the translation happens inside of the localization framework. Similarly L20n takes care of the interpolation of external variables into the translations. As a developer, all you need to do is declare which translation identifier you are interested in and pass the raw data that is relevant.
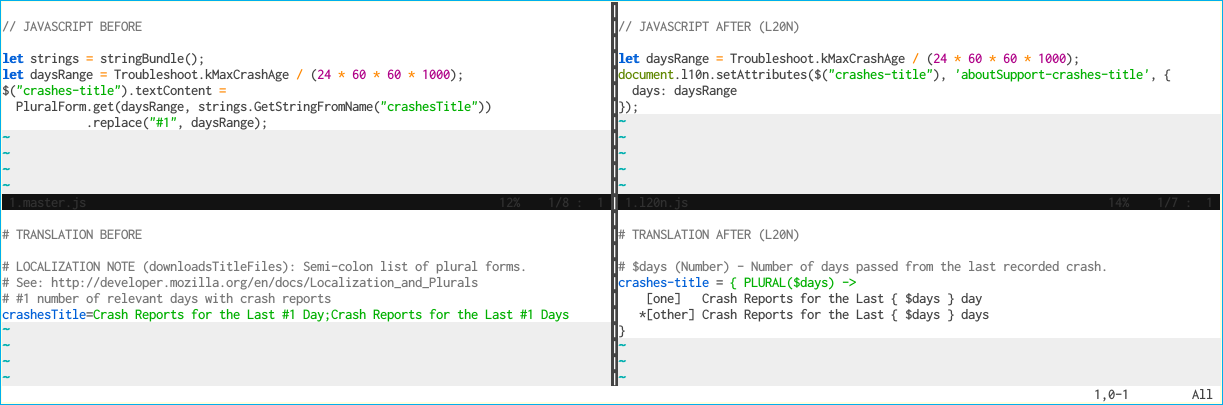
Fig. 2. Plurals and interpolation in L20n
In the example above you’ll note that in the BEFORE version the developer had to manually call the PluralForm API. Furthermore the calling code is also responsible for replacing #1 with the relevant datum. There’s is no error checking: if the translation contains an error (perhaps a typo in #1) the replace() will silently fail and the final message displayed to the user will be broken.
Separation of Concerns: Intl Formatters
L20n builds on top of the existing standards like ECMA 402’s Intl API (itself based in large part on Unicode’s ICU). The Localization team has also been active in advancing proposals and specification for new formatters.
L20n provides an easy way to use Intl formatters from within translations. Often times the Intl API completely removes the need of going through the localization layer. In the example below the logic for displaying relative time (“2 days ago”) has been replaced by a single call to a new Intl formatter, Intl.RelativeTimeFormat.
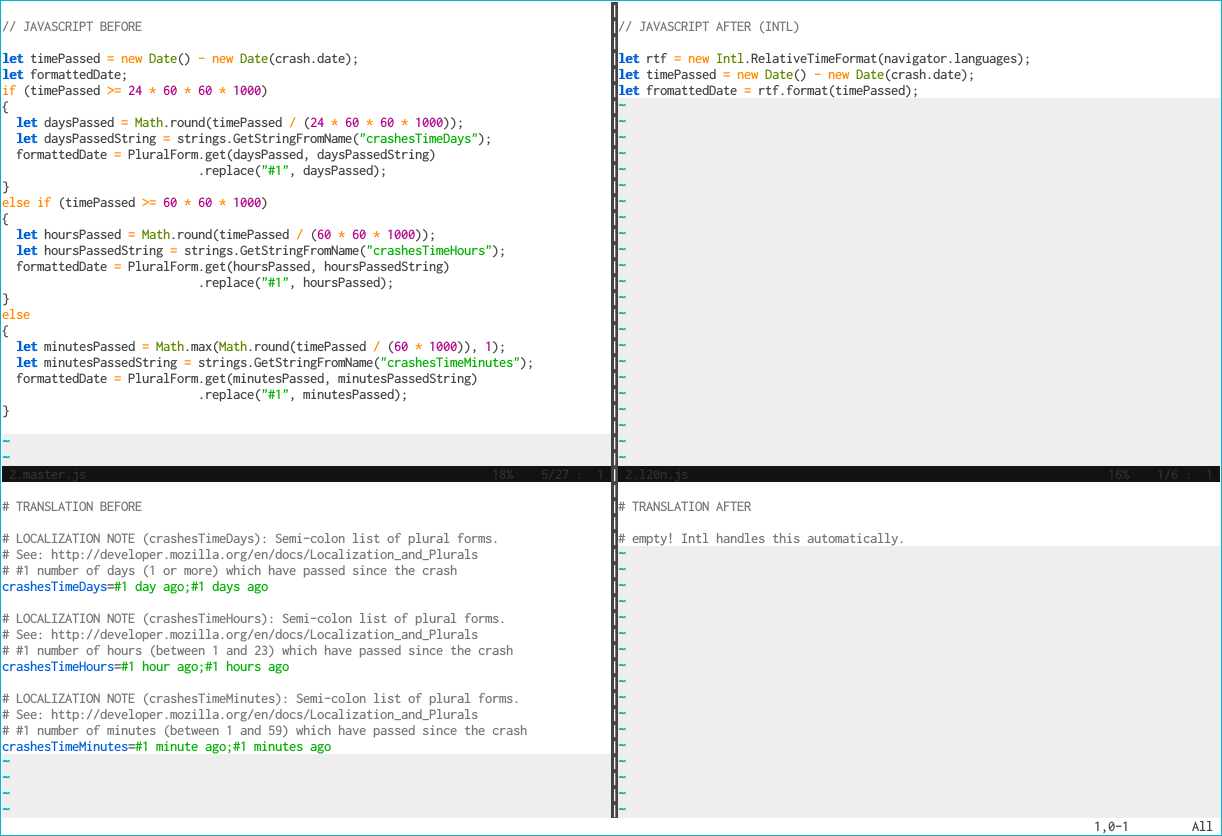
Fig. 3. Intl API in use
Separation of Concerns: HTML in Translations
L20n allows for some semantic markup in translations. Localizers can use safe text-level HTML elements to create translations which obey the rules of typography and punctuation. Developers can also embed interactive elements inside of translations and attach event handlers to them in HTML or XUL. L20n will overlay translations on top of the source DOM tree preserving the identity of elements and the event listeners.
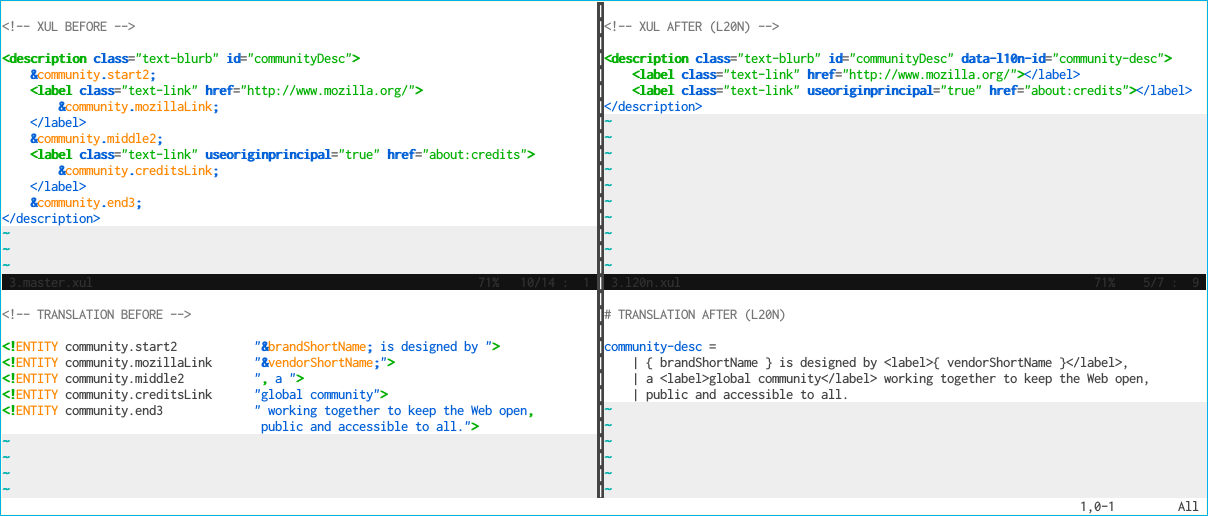
Fig. 4. Semantic markup in L20n
In the example above the BEFORE version must resort to splitting the translation into multiple parts, each for a possible piece of translation surrounding the two <label> elements. The L20n version only defines a single translation unit and the localizer is free to position the text around the <label> elements as they see fit. In the future it will be possible to reorder the <label> elements themselves.
Resilient to Errors
L20n provides a graceful and robust fallback mechanism in case of missing or broken translations. If you’re a Firefox front-end developer you might be familiar with this image:

Fig. 5. Yellow Screen of Death
This errors happens whenever a DTD file is broken. The way a DTD file can be broken might be as subtle as a translation using the … entity which is valid in HTML but not in XUL.
In L20n, broken translations never break the UI. L20n tries its best to display a meaningful message to the user in case of errors. It may try to fall back to the next language preferred by the user if it’s available. As the last resort L20n will show the identifier of the message.
New Features
L20n allows us to re-think major design decisions related to localization in Firefox. The first area of innovation that we’re currently exploring is the experience of changing the browser’s UI language. A runtime localization framework allows the change to happen seamlessly on the fly without restarts. It will also become possible to go back and forth between languages for just a part of the UI, a feature often requested by non-English users of Developer Tools.
Another innovation that we’re excited about is the ability to push updates to the existing translations independent of the software updates which currently happen approximately every 6 weeks. We call this feature Live Updates to Localizations.
We want to decouple the release schedule of Firefox from the release schedule of localizations. The whole release process can then become more flexible and new translations can be delivered to users outside of regular software updates.
Recap
L20n’s goal is to improve Mozilla’s ability to create quality multilingual user interfaces, simplify the localization process for developers, improve error recovery and allow us to innovate.
The migration will result in cleaner and easier to maintain code base. It will improve the quality and the security of Firefox. It will provide a resilient runtime fallback, loosening the ties between code and localizations. And it will open up many new opportunities to innovate.
Nemo wrote on
Staś Małolepszy wrote on
Simon wrote on
Staś Małolepszy wrote on
Simon wrote on
Satya wrote on