Quite often, an imperfect translation is better than no translation. So why even publish untranslated content when high-quality machine translation systems are fast and affordable? Why not immediately machine-translate content and progressively ship enhancements as they are submitted by human translators?
At Mozilla, we call this process pretranslation. We began implementing it in Pontoon before COVID-19 hit, thanks to Vishal who landed the first patches. Then we caught some headwinds and didn’t make much progress until 2022 after receiving a significant development boost and finally launched it for the general audience in September 2023.
So far, 20 of our localization teams (locales) have opted to use pretranslation across 15 different localization projects. Over 20,000 pretranslations have been submitted and none of the teams have opted out of using it. These efforts have resulted in a higher translation completion rate, which was one of our main goals.
In this article, we’ll take a look at how we developed pretranslation in Pontoon. Let’s start by exploring how it actually works.
How does pretranslation work?
Pretranslation is enabled upon a team’s request (it’s off by default). When a new string is added to a project, it gets automatically pretranslated using a 100% match from translation memory (TM), which also includes translations of glossary entries. If a perfect match doesn’t exist, a locale-specific machine translation (MT) engine is used, trained on the locale’s translation memory.
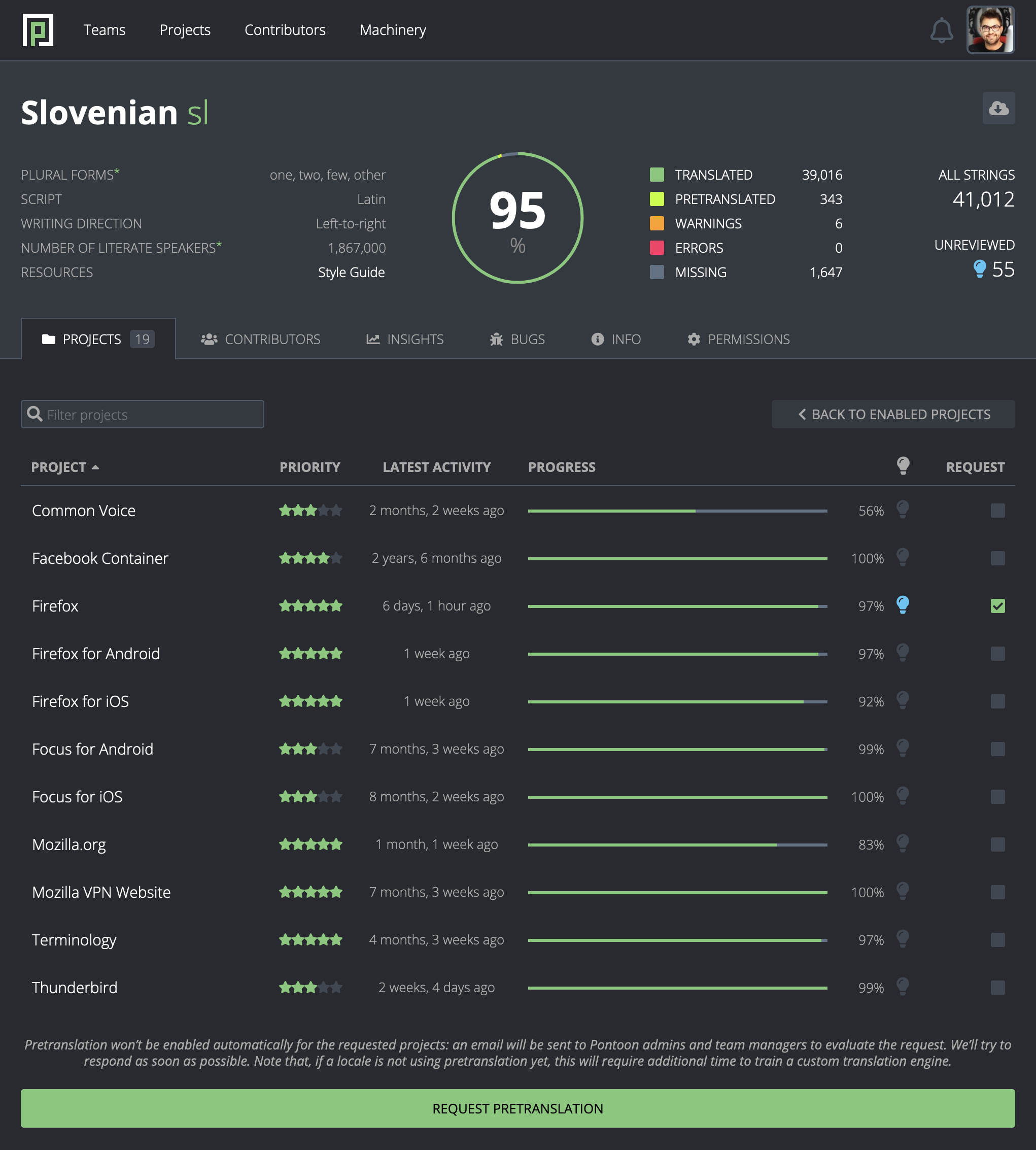
Pretranslation opt-in form.
After pretranslations are retrieved and saved in Pontoon, they get synced to our primary localization storage (usually a GitHub repository) and hence immediately made available for shipping. Unless they fail our quality checks. In that case, they don’t propagate to repositories until errors or warnings are fixed during the review process.
Until reviewed, pretranslations are visually distinguishable from user-submitted suggestions and translations. This makes post-editing much easier and more efficient. Another key factor that influences pretranslation review time is, of course, the quality of pretranslations. So let’s see how we picked our machine translation provider.
Choosing a machine translation engine
We selected the machine translation provider based on two primary factors: quality of translations and the number of supported locales. To make translations match the required terminology and style as much as possible, we were also looking for the ability to fine-tune the MT engine by training it on our translation data.
In March 2022, we compared Bergamot, Google’s Cloud Translation API (generic), and Google’s AutoML Translation (with custom models). Using these services we translated a collection of 1,000 strings into 5 locales (it, de, es-ES, ru, pt-BR), and used automated scores (BLEU, chrF++) as well as manual evaluation to compare them with the actual translations.
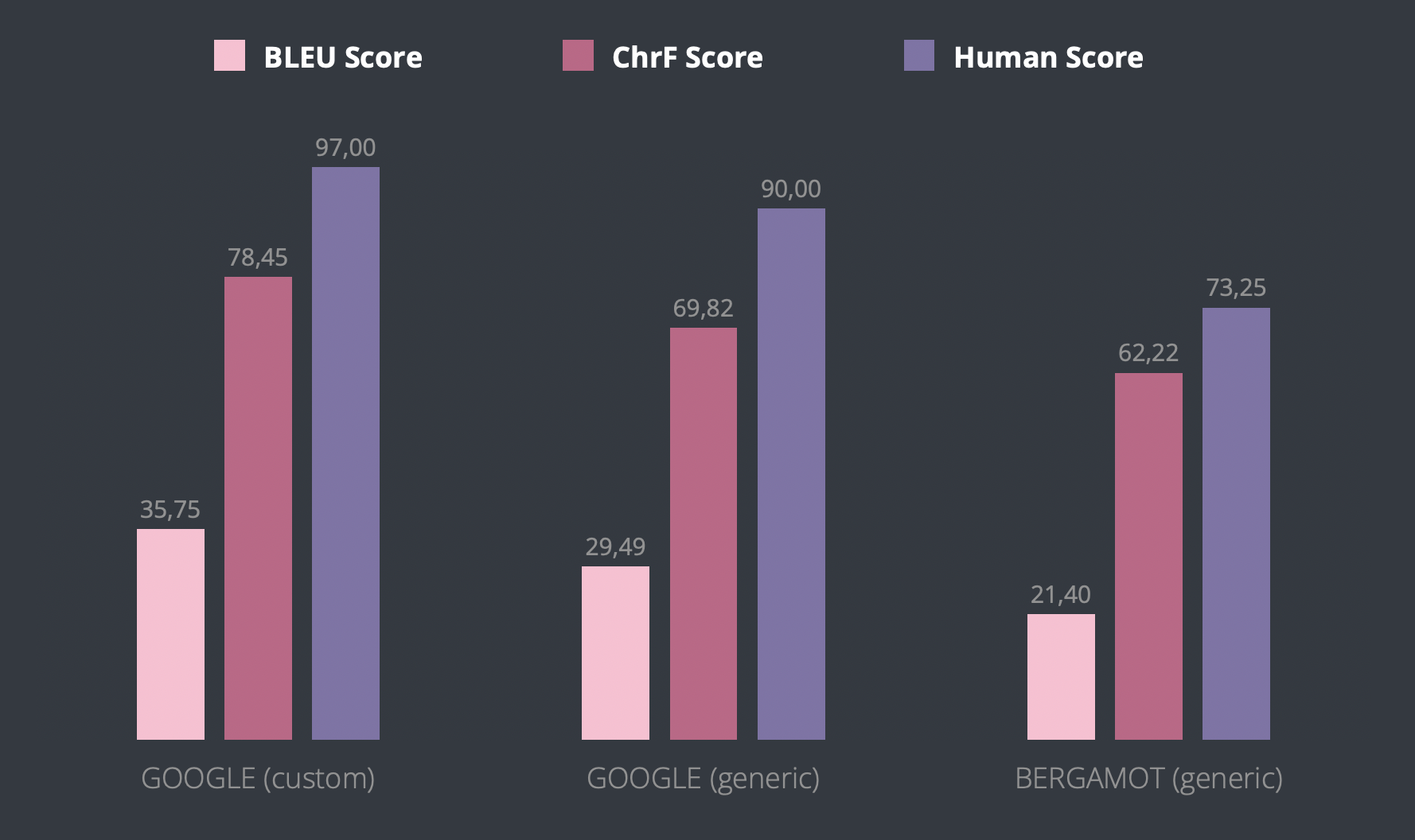
Performance of tested MT engines for Italian (it).
Google’s AutoML Translation outperformed the other two candidates in virtually all tested scenarios and metrics, so it became the clear choice. It supports over 60 locales. Google’s Generic Translation API supports twice as many, but we currently don’t plan to use it for pretranslation in locales not supported by Google’s AutoML Translation.
Making machine translation actually work
Currently, around 50% of pretranslations generated by Google’s AutoML Translation get approved without any changes. For some locales, the rate is around 70%. Keep in mind however that machine translation is only used when a perfect translation memory match isn’t available. For pretranslations coming from translation memory, the approval rate is 90%.
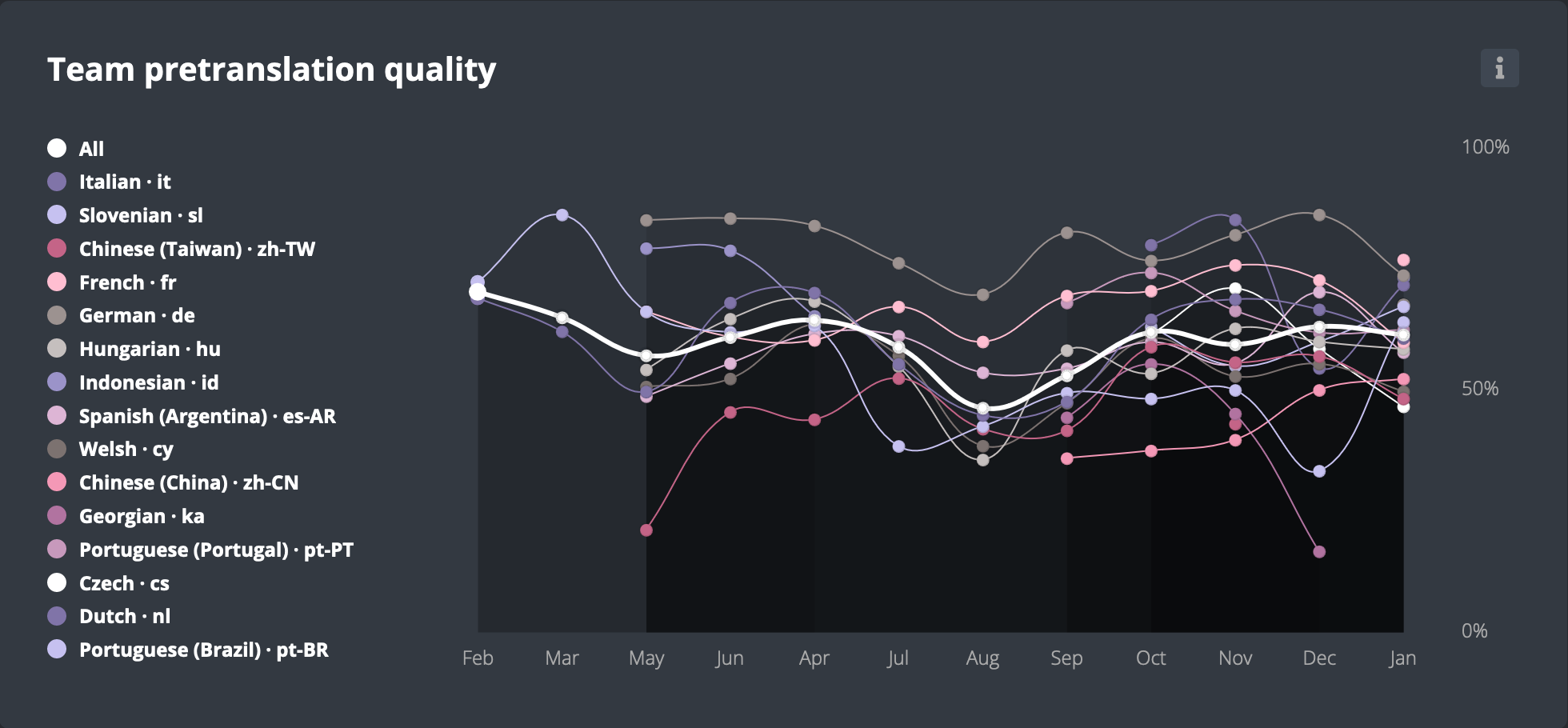
Comparison of pretranslation approval rate between teams.
To reach that approval rate, we had to make a series of adjustments to the way we use machine translation.
For example, we convert multiline messages to single-line messages before machine-translating them. Otherwise, each line is treated as a separate message and the resulting translation is of poor quality.
Multiline message:
Make this password unique and different from any others you use. A good strategy to follow is to combine two or more unrelated words to create an entire pass phrase, and include numbers and symbols.
Multiline message converted to a single-line message:
Make this password unique and different from any others you use. A good strategy to follow is to combine two or more unrelated words to create an entire pass phrase, and include numbers and symbols.
Let’s take a closer look at two of the more time-consuming changes.
The first one is specific to our machine translation provider (Google’s AutoML Translation). During initial testing, we noticed it would often take a long time for the MT engine to return results, up to a minute. Sometimes it even timed out! Such a long response time not only slows down pretranslation, it also makes machine translation suggestions in the translation editor less useful – by the time they appear, the localizer has already moved to translate the next string.
After further testing, we began to suspect that our custom engine shuts down after a period of inactivity, thus requiring a cold start for the next request. We contacted support and our assumption was confirmed. To overcome the problem, we were advised to send a dummy query to the service every 60 seconds just to keep the system alive.

Image source: Giphy.
Of course, it’s reasonable to shut down inactive services to free up resources, but the way to keep them alive isn’t. We have to make (paid) requests to each locale’s machine translation engines every minute just to make sure they work when we need them. And sometimes even that doesn’t help – we still see about a dozen ServiceUnavailable errors every day. It would be so much easier if we could just customize the default inactivity period or pay extra for an always-on service.
The other issue we had to address is quite common in machine translation systems: they are not particularly good at preserving placeholders. In particular, extra space often gets added to variables or markup elements, resulting in broken translations.
Message with variables:
{ $partialSize } of { $totalSize }
Message with variables machine-translated to Slovenian (adding space after $ breaks the variable):
{$ partialSize} od {$ totalSize}
We tried to mitigate this issue by wrapping placeholders in <span translate=”no”>…</span>, which tells Google’s AutoML Translation to not translate the wrapped text. This approach requires the source text to be submitted as HTML (rather than plain text), which triggers a whole new set of issues — from adding spaces in other places to escaping quotes — and we couldn’t circumvent those either. So this was a dead-end.
The solution was to store every placeholder in the Glossary with the same value for both source string and translation. That approach worked much better and we still use it today. It’s not perfect, though, so we only use it to pretranslate strings for which the default (non-glossary) machine translation output fails our placeholder quality checks.
Making pretranslation work with Fluent messages
On top of the machine translation service improvements we also had to account for the complexity of Fluent messages, which are used by most of the projects we localize at Mozilla. Fluent is capable of expressing virtually any imaginable message, which means it is the localization system you want to use if you want your software translations to sound natural.
As a consequence, Fluent message format comes with a syntax that allows for expressing such complex messages. And since machine translation systems (as seen above) already have trouble with simple variables and markup elements, their struggles multiply with messages like this:
shared-photos =
{ $photoCount ->
[one]
{ $userGender ->
[male] { $userName } added a new photo to his stream.
[female] { $userName } added a new photo to her stream.
*[other] { $userName } added a new photo to their stream.
}
*[other]
{ $userGender ->
[male] { $userName } added { $photoCount } new photos to his stream.
[female] { $userName } added { $photoCount } new photos to her stream.
*[other] { $userName } added { $photoCount } new photos to their stream.
}
}
That means Fluent messages need to be pre-processed before they are sent to the pretranslation systems. Only relevant parts of the message need to be pretranslated, while syntax elements need to remain untouched. In the example above, we extract the following message parts, pretranslate them, and replace them with pretranslations in the original message:
- { $userName } added a new photo to his stream.
- { $userName } added a new photo to her stream.
- { $userName } added a new photo to their stream.
- { $userName } added { $photoCount } new photos to his stream.
- { $userName } added { $photoCount } new photos to her stream.
- { $userName } added { $photoCount } new photos to their stream.
To be more accurate, this is what happens for languages like German, which uses the same CLDR plural forms as English. For locales without plurals, like Chinese, we drop plural forms completely and only pretranslate the remaining three parts. If the target language is Slovenian, two additional plural forms need to be added (two, few), which in this example results in a total of 12 messages needing pretranslation (four plural forms, with three gender forms each).
Finally, Pontoon translation editor uses custom UI for translating access keys. That means it’s capable of detecting which part of the message is an access key and which is a label the access key belongs to. The access key should ideally be one of the characters included in the label, so the editor generates a list of candidates that translators can choose from. In pretranslation, the first candidate is directly used as an access key, so no TM or MT is involved.
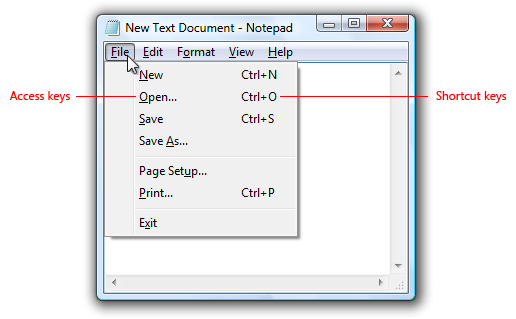
Access keys (not to be confused with shortcut keys) are used for accessibility to interact with all controls or menu items using the keyboard. Windows indicates access keys by underlining the access key assignment when the Alt key is pressed. Source: Microsoft Learn.
Looking ahead
With every enhancement we shipped, the case for publishing untranslated text instead of pretranslations became weaker and weaker. And there’s still room for improvements in our pretranslation system.
Ayanaa has done extensive research on the impact of Large Language Models (LLMs) on translation efficiency. She’s now working on integrating LLM-assisted translations into Pontoon’s Machinery panel, from which localizers will be able to request alternative translations, including formal and informal options.
If the target locale could set the tone to formal or informal on the project level, we could benefit from this capability in pretranslation as well. We might also improve the quality of machine translation suggestions by providing existing translations into other locales as references in addition to the source string.
If you are interested in using pretranslation or already use it, we’d love to hear your thoughts! Please leave a comment, reach out to us on Matrix, or file an issue.
No comments yet
Post a comment