In case you’re not familiar with the acronym, CLDR stands for Common Locale Data Repository: it’s a repository of locale data maintained by the Unicode Consortium, and used in several libraries that power internationalization (i18n) features in products developed by Mozilla, Apple, IBM, Microsoft, and many other companies. Firefox uses the data provided by CLDR mostly through the ICU library.
You can find an exhaustive list of the type of data provided in the CLDR home page. Within Firefox, these are currently the main focus areas:
- Date and time formatting, calendar preferences.
- Plural cases.
- Translation of language and region names.
Date and time formatting, calendar preferences
Firefox 57 shipped with a native datetime picker that can be used in HTML forms. Here’s how it looks in Italian:
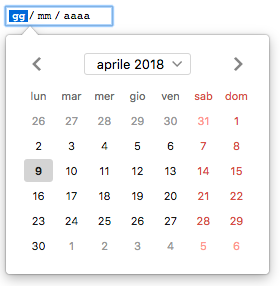 The localization data used to generate this dialog comes from CLDR:
The localization data used to generate this dialog comes from CLDR:
- Date formatting for the placeholder.
- Month and day names.
- First day of the week (e.g. Sunday for en-US, Monday for it).
The same data is also available to Firefox developers to properly internationalize other parts of the user interface. It’s provided via an API called ‘mozIntl’, which extends the standard JavaScript Internalization library (ECMA402).
Firefox 61 will also ship with a relative time format API (“in 5 seconds”, “5 seconds ago”), finally allowing front-end developers to use a more natural language in the interface.
Plural cases
Currently, there are 3 completely different sources of truth for plurals:
- Fluent uses CLDR to determine the number of plural forms for each language, and CLDR categories (zero, one, two, few, other, many).
- Pontoon stores its own internal rules, using CLDR categories.
- Gecko stores an internal plural rule, in form of a localizable key with an integer value. Each rule maps to a different number of plural forms, and doesn’t have any relation with CLDR.
It suffices to say that this fragmentation generated a lot of inconsistencies over the years.
Given the renewed focus on Fluent, last December I started analyzing all Gecko plural forms, to identify inconsistencies between our settings and CLDR. This led to correcting the plural form for 10 languages by aligning with the CLDR values. In a couple of cases, I also reported issues back to CLDR: for Macedonian our ticket was accepted and the changes included, for Latvian it was rejected.
A significant amount of time was also invested in correcting errors in Gecko before starting migrating strings to Fluent: several locales had a wrong number of plural forms, but weren’t aware of the issue, given the hacky nature of plural support in .properties. Starting from January, dashboards are reporting this type of errors, allowing localizers to quickly correct them. Soon, these errors will be reported directly in Pontoon when submitting a new translation.
Work is still underway to fix plurals in other projects in Pontoon, and minimize the impact on localizers: for example, if a string moves from 2 plural forms to 6, you need to invalidate existing translations, and possibly copy over one of the existing values to reduce the need for copy and paste.
Translation of language and region names
Localized names for languages and regions are used in Firefox preferences and other parts of the UI. They’re defined as localizable strings in toolkit, and currently consist of 203 language names and 272 region names.
 Since CLDR provides this data as well, the plan is to start using it to localize Firefox UI. This poses a few challenges:
Since CLDR provides this data as well, the plan is to start using it to localize Firefox UI. This poses a few challenges:
- Can we replace the current list of country names from GENC with region names from CLDR? This proposal already received a green light.
- What data is missing from CLDR? We ship languages that are missing from CLDR, we’ll need to file tickets to get those language names added.
- Since we already have localized names, can we compare them with data from CLDR and see how big the difference is? Strictly related: can the CLDR data be used directly?
Right now, the work is mostly focused on the last point, and tracked in this bug. I started analyzing the difference for a couple of languages, including my own (Italian):
- 53 language names (26.11%) were translated differently between Mozilla and CLDR. After comparing the two translations for each name to identify the best one, in most cases conflicts were resolved by using the CLDR data. Only seven differences remain after this work (3.45%), with five improvements that need to be reported back to CLDR using their Survey Tool. Two more differences are expected, since they are caused by differences in the English source (Frysian vs Western Frysian, Rundi vs Kirundi).
- 51 region names were translated differently (18.75%). After, only 11 differences remain (4.04%).
- Language names are not usable directly: in Mozilla they’re uppercase, since they’re only used as stand-alone labels. In CLDR they’re all lowercase, since the language name is always lowercase when used in the middle of a sentence in Italian.
Analysis is now moving to other languages, with higher percentage of differences. The average difference for language names is 45.49%, while for region names is 30.80%, but we have locales with up to 96% of differences, and we need to figure out why that happens.
The full statistical analysis is available in this spreadsheet. If you’re interested in getting a list of the actual differences for your language, feel free to reach out. One thing to keep in mind is that there are differences for English itself, e.g. “Acoli” vs “Acholi”, or “Caribbean Netherlands” vs “Bonaire, Sint Eustatius, and Saba”, and this inevitably affects the data.
Next steps for 2018
Fluent represents the future of localization for Mozilla products, and it relies heavily on CLDR data. But that’s not the only reason to invest resources in improving the CLDR integration within Firefox:
- Using CLDR means unifying our approach to internationalization data with the one used in products like Windows, macOS, Android, Twitter, Wikipedia, etc. It also means offering a consistent and more familiar experience to our users.
- It lowers the burden on our localizers. What’s the point of translating hundreds of strings, if there is an established, high-quality dataset that could be safely reused? This data is a live archive, collected and maintained by a large body of linguistic experts cooperating on CLDR, and exposed on a daily basis to millions of users.
- We can help extending CLDR support to minority languages that are not relevant for commercial software companies. For example, Firefox Nightly currently ships in 101 languages. While Microsoft covers about the same number of languages through Windows language packs, other browsers support half that number (or less).
As already seen, some parts of UI already use CLDR data: if a locale is not available in the CLDR repository, it won’t have a localized datetime picker, or properly localized dates, and it won’t pick the right plural form when using Fluent strings.
In the coming months we’re going to invest resources on building a pathway for locales to be included as seed locales in CLDR: it will likely be a stand-alone project in Pontoon, with Fluent as storage format, used to collect information that will be converted and used to bootstrap locale data in CLDR. Kekoa, who will be back as a intern in the summer, will contribute to this project (among other things).
We also plan to extend mozIntl API to provide localized language and region names. The current idea is to generate a local data source from CLDR, and integrate it with our own data for locales that are not yet available in the CLDR repository. In order to do that, we need to keep investigating the differences between our current translations and CLDR, and identify potential issues before fully switching to CLDR as source for this data.
No comments yet
Post a comment